
需求背景
在多租户的场景下,提供一种跨namespace的资源“借用”途径,在资源池建设之后进一步提升资源的利用率。在还资源过程中,期望能够控制对原来跨ns借用资源的应用进行“延迟”释放,控制驱逐Pod的顺序,保障原来优先级较高的应用不会被优先处理。
用户故事
应用类别分为 训练任务和在线任务。
训练任务一般采用分布式训练,但是其Pod副本数是可以适当弹性浮动的,即比如副本数为3~6之间都可以接受。在线服务可以理解为服务可能在用户开通之后就一直存在,客观情况下除非用户主动删除在线服务,否则在资源满足的情况下不会主动释放其占用的服务。简单描述即当资源可能不够的情况下,在需要自动释放资源的时候,在线服务是 “延迟” 释放资源,优先对那些训练任务“动手”。
- 用户A配置了 {resources:{min:6, max:10}} 的资源限额,用户B的资源限额配置为 {resources: {min:12,max:14}}
- 用户A Job 应用资源配置为{resources:{requests:2,limits:2}} rs为2,NoteBook 应用资源配额为{resources:{requests:2,limits:2}} rs 为2
- 用户B Job-1 应用资源配置为{resources:{requests:3,limits:3}} rs为1,
Job-2 应用资源配置为{resources:{resources:5,limits:5}} rs为1。
背景如上,模拟过程步骤及期望如下:
- 在ns-A中运行Job,在ns-B中运行Job-1,由于此时requests都没有达到min值,此时在各自的ns中都能正常运行。
- 在ns-A中运行NoteBokk服务,这个时候 22+22>6那么需要向ns-B借用部分资源进行运行
- 在ns-B中运行Job-2服务,这个时候ns-B通知ns-A:”大兄嘚,临时借用的资源该还我了,”,此时在ns-A中,由于NoteBook服务是在线服务,需要保障其在 “不得已” 情况下才释放资源以备还回借用的资源,此时应该是优先释放Job 资源来还债。
需求解析
- 跨namespace资源借用
- 控制pod释放资源的先后顺序。
以下情况举例以CPU资源为例,Memory,GPU一样适用
跨namespace资源调用
解决方案: 基于scheduler framework 定义 capacityScheduling 调度策略。scheduler framework。
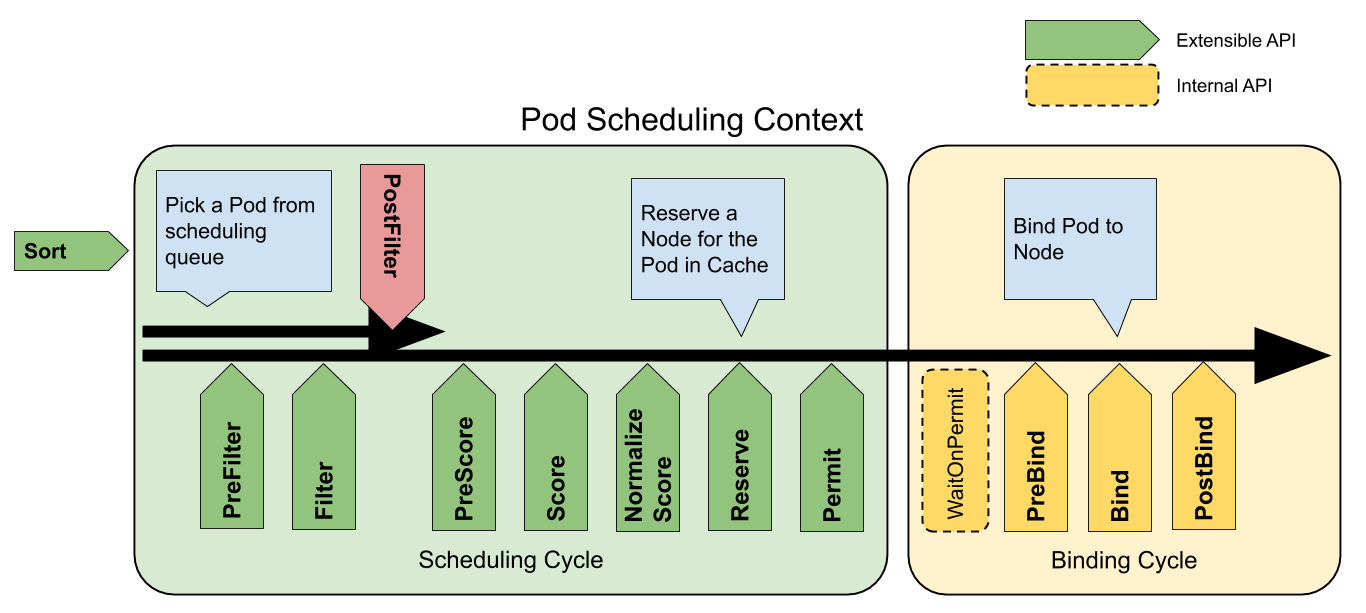
通过在调度框架中完成对应的Points逻辑,详细的代码分析后续分析scheduler framework进行介绍。
控制资源释放的先后顺序
解决方案: 基于PriorityClass的优先级与抢占式,PriorityClass优先级与抢占。
优先级的概念我们都可以理解,即优先级越高则优先抢占资源,固引入对NoteBook关联的PriorityClass的定义:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: priority-class-for-notebook
value: 1000000
globalDefault: false
description: "This priority class should be used for notebook service pods only.
注意,这是一个全局性质的定义,不会因为namespace而控制。
那怎么知道还资源释放是和优先级相关的呢?
根据函数名 selectVictimsOnNode,我们可以知道这边是选择那些“倒霉蛋”来释放他们借用的资源,具体关键逻辑性的代码如下:
...
// 此处自定义了排序逻辑
sort.Slice(nodeInfo.Pods, func(i, j int) bool { return !util.MoreImportantPod(nodeInfo.Pods[i].Pod, nodeInfo.Pods[j].Pod) })
var potentialVictims []*v1.Pod
if preemptorWithElasticQuota {
for _, p := range nodeInfo.Pods {
pElasticQuotaInfo, pWithElasticQuota := elasticQuotaInfos[p.Pod.Namespace]
if !pWithElasticQuota {
continue
}
if moreThanMinWithPreemptor {
// If Preemptor.Request + Quota.Used > Quota.Min:
// It means that its guaranteed isn't borrowed by other
// quotas. So that we will select the pods which subject to the
// same quota(namespace) with the lower priority than the
// preemptor's priority as potential victims in a node.
if p.Pod.Namespace == pod.Namespace && podutil.GetPodPriority(p.Pod) < podPriority {
potentialVictims = append(potentialVictims, p.Pod)
if err := removePod(p.Pod); err != nil {
return nil, 0, false
}
}
} else {
// If Preemptor.Request + Quota.allocated <= Quota.min: It
// means that its min(guaranteed) resource is used or
// `borrowed` by other Quota. Potential victims in a node
// will be chosen from Quotas that allocates more resources
// than its min, i.e., borrowing resources from other
// Quotas.
if p.Pod.Namespace != pod.Namespace && moreThanMin(*pElasticQuotaInfo.Used, *pElasticQuotaInfo.Min) {
// 将选择好的 POD 添加到Victims数组中
potentialVictims = append(potentialVictims, p.Pod)
if err := removePod(p.Pod); err != nil {
return nil, 0, false
}
}
}
}
} else {
for _, p := range nodeInfo.Pods {
_, pWithElasticQuota := elasticQuotaInfos[p.Pod.Namespace]
if pWithElasticQuota {
continue
}
if podutil.GetPodPriority(p.Pod) < podPriority {
potentialVictims = append(potentialVictims, p.Pod)
if err := removePod(p.Pod); err != nil {
return nil, 0, false
}
}
}
}
我们再来看看 util.MoreImportantPod 这个排序的具体逻辑:
func MoreImportantPod(pod1, pod2 *v1.Pod) bool {
p1 := podutil.GetPodPriority(pod1)
p2 := podutil.GetPodPriority(pod2)
if p1 != p2 {
return p1 > p2
}
return GetPodStartTime(pod1).Before(GetPodStartTime(pod2))
}
到了这边就一切了然了,实际上优先根据优先级排序,如果优先级相同的话则根据StartTime进行排序。
至此算完成了,但是果真如此么?这里我们引入了PriorityClass来控制释放资源的顺序,那么会不会引入其他问题呢?
谨惕
引入高优先级,那么默认情况下会导致资源抢占,那么低优先级的应用在高优先级应用不主动释放资源的情况下永远获取不到资源,最恶劣的结果就是低优先级的Pod一直处于“资源饥饿”状态,始终没法部署运行。那么我们有没有机会在利用优先级的同时,弱化抢占的行为能力呢?答案是肯定的,官方文档中有关于非抢占式的 PriorityClass的明细描述,通过以上的组合,可以达到目前我们的需求预期,下面让我们来验证测试。
验证测试
测试环境为
1 master unscheable 8核
2 slave scheable 8*2 核
kube-scheduler 编译完成之后需要对kube-scheduler配置对应的调度策略:
# kube-scheduler.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-scheduler
tier: control-plane
name: kube-scheduler-with-plugins
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
// modify
- --config=/etc/kubernetes/scheduler-plugins/sched-multi.yaml
- --port=0
image: kirago/kube-scheduler:v0.19.8
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /healthz
port: 10259
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
name: kube-scheduler-with-plugins
resources:
requests:
cpu: 100m
startupProbe:
failureThreshold: 24
httpGet:
host: 127.0.0.1
path: /healthz
port: 10259
scheme: HTTPS
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
volumeMounts:
- mountPath: /etc/kubernetes/scheduler.conf
name: kubeconfig
readOnly: true
// modify
- mountPath: /etc/kubernetes/scheduler-plugins/sched-multi.yaml
name: sched-multi
readOnly: true
hostNetwork: true
priorityClassName: system-node-critical
volumes:
- hostPath:
path: /etc/kubernetes/scheduler.conf
type: FileOrCreate
name: kubeconfig
// modify
- hostPath:
path: /etc/kubernetes/scheduler-plugins/sched-multi.yaml
type: FileOrCreate
name: sched-multi
status: {}
# sched-multi.yaml
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
clientConnection:
kubeconfig: /etc/kubernetes/scheduler.conf
profiles:
- schedulerName: default-scheduler
plugins:
preFilter:
enabled:
- name: CapacityScheduling
postFilter:
enabled:
- name: CapacityScheduling
disabled:
- name: "*"
reserve:
enabled:
- name: CapacityScheduling
postBind:
enabled:
# pluginConfig is needed for coscheduling plugin to manipulate PodGroup CR objects.
pluginConfig:
- name: CapacityScheduling
args:
kubeConfigPath: /etc/kubernetes/scheduler.conf
由于 scheduler plugins*是sig-scheduling维护,目前这块的文档还是比较少的,这边的插件目前属于out-of-tree,这边的Option是merge到in-tree中的,所以每个Point该怎么配,最直观的就是看下源码,这是最靠谱的,之前在配置coScheduling的时候就遇到一丢丢问题,个人也提交了个ISSUE确认了下,详见
The Pod of kube-scheduler : "found unknown field: unreserve"。
权限准备工作
// all-in-one.yaml
# First part
# Apply extra privileges to system:kube-scheduler.
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: system:kube-scheduler:plugins
rules:
- apiGroups: ["scheduling.sigs.k8s.io"]
resources: ["elasticquotas"]
verbs: ["get", "list", "watch", "create", "delete", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: system:kube-scheduler:plugins
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-scheduler:plugins
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: system:kube-scheduler
---
创建对应的namespace
// eq-ns.yaml
// ns-A
apiVersion: v1
kind: Namespace
metadata:
name: eq1
---
// ns-B
apiVersion: v1
kind: Namespace
metadata:
name: eq2
创建CRD文件
// capacityscheduler-crd.yaml
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: elasticquotas.scheduling.sigs.k8s.io
annotations:
"api-approved.kubernetes.io": "https://github.com/kubernetes-sigs/scheduler-plugins/pull/52"
spec:
group: scheduling.sigs.k8s.io
names:
plural: elasticquotas
singular: elasticquota
kind: ElasticQuota
shortNames:
- eq
- eqs
scope: Namespaced
versions:
- name: v1alpha1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
min:
type: object
additionalProperties:
anyOf:
- type: integer
- type: string
pattern: ^(\+|-)?(([0-9]+(\.[0-9]*)?)|(\.[0-9]+))(([KMGTPE]i)|[numkMGTPE]|([eE](\+|-)?(([0-9]+(\.[0-9]*)?)|(\.[0-9]+))))?$
x-kubernetes-int-or-string: true
max:
type: object
additionalProperties:
anyOf:
- type: integer
- type: string
pattern: ^(\+|-)?(([0-9]+(\.[0-9]*)?)|(\.[0-9]+))(([KMGTPE]i)|[numkMGTPE]|([eE](\+|-)?(([0-9]+(\.[0-9]*)?)|(\.[0-9]+))))?$
x-kubernetes-int-or-string: true
status:
type: object
properties:
used:
type: object
additionalProperties:
anyOf:
- type: integer
- type: string
pattern: ^(\+|-)?(([0-9]+(\.[0-9]*)?)|(\.[0-9]+))(([KMGTPE]i)|[numkMGTPE]|([eE](\+|-)?(([0-9]+(\.[0-9]*)?)|(\.[0-9]+))))?$
x-kubernetes-int-or-string: true
创建NoteBook关联的PriorityClass
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: priority-class-for-notebook
value: 1000000
preemptionPolicy: Never
globalDefault: false
description: "This priority class should be used for notebook service pods only."
模拟场景所需的Deployment
// Job
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx1-1
namespace: eq1
labels:
app: nginx1-1
spec:
replicas: 2
selector:
matchLabels:
app: nginx1-1
template:
metadata:
name: nginx1-1
labels:
app: nginx1-1
spec:
containers:
- name: nginx
image: nginx
command: ["/bin/bash", "-c", "cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null"]
resources:
limits:
cpu: 2
requests:
cpu: 2
// NoteBooK
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx2-1
namespace: eq1
labels:
app: nginx2-1
spec:
replicas: 2
selector:
matchLabels:
app: nginx2-1
template:
metadata:
name: nginx2-1
labels:
app: nginx2-1
annotations:
job: notebook
spec:
containers:
- name: nginx
image: nginx
command: ["/bin/bash", "-c", "cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null"]
resources:
limits:
cpu: 2
requests:
cpu: 2
priorityClassName: priority-class-for-notebook
// Job 1
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx1-2
namespace: eq2
labels:
app: nginx1-2
spec:
replicas: 1
selector:
matchLabels:
app: nginx1-2
template:
metadata:
name: nginx1-2
labels:
app: nginx1-2
spec:
containers:
- name: nginx
image: nginx
command: ["/bin/bash", "-c", "cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null"]
resources:
limits:
cpu: 3
requests:
cpu: 3
// Job-2
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx2-2
namespace: eq2
labels:
app: nginx2-2
spec:
replicas: 1
selector:
matchLabels:
app: nginx2-2
template:
metadata:
name: nginx2-2
labels:
app: nginx2-2
spec:
containers:
- name: nginx
image: nginx
command: ["/bin/bash", "-c", "cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null"]
resources:
limits:
cpu: 5
requests:
cpu: 5
- 部署 Job

- 部署 Job-1

- 部署 NoteBook,此时模拟ns-A按照我们的预期 22+22>6,且 ns-B 空间用户的资源还有剩余满足借用的前提,即使 8>6 但是也是能够将ns-A中所有的应用部署起来的。

- 部署模拟 ns-B 中的Job-2,此时这个时候ns-B肯定会优先保障自家兄弟的温饱,此时ns-A中借用的资源应该还回来了,但是应该还谁的资源呢?根据上文的分析实际上再ns-A中也分三六九等,需要优先保障NoteBook服务,那么就是对Job进行下手。

可以看到,一切按照我们的预期在执行,至此,各位大佬可以发现,此处的pod nginx1-1-59457d7fbf-4pkxt是一个pending状态,为啥不是直接被干掉呢?