在mysql数据库中,我们习惯的使用left join 去查询两个表的数据。比如说,有这么一个表,我要去查询所有有java这个标签的文章。
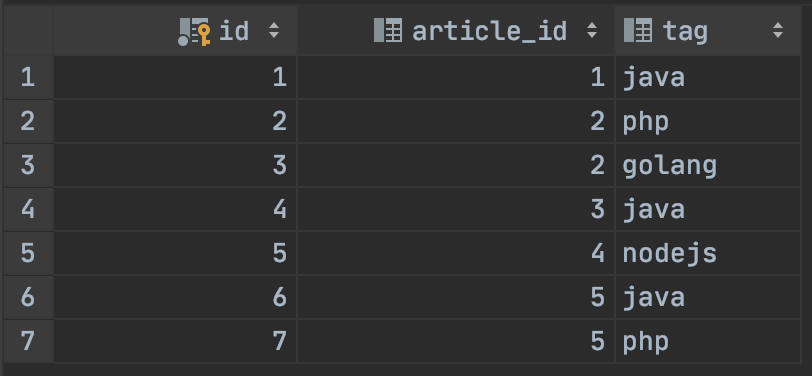
当然,这个是 一个很简单表结构,我们要查出有java标签的,这个sql很简单。
select * from tags where tag='java'
结果很明显,也很简单
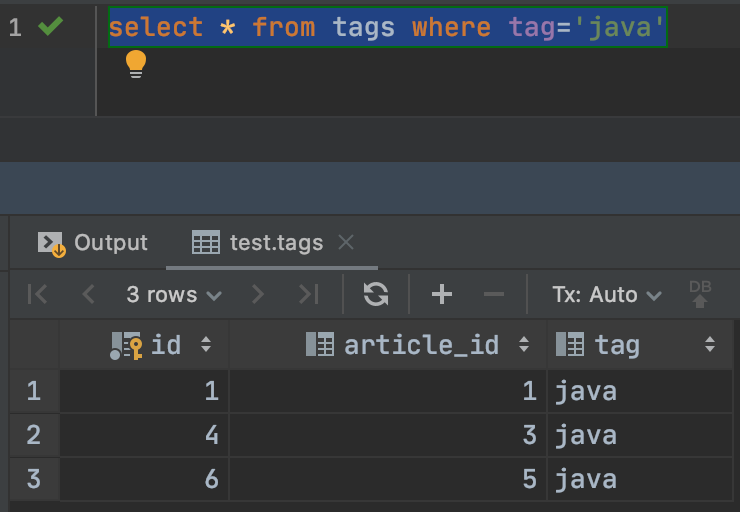
这是一个简单的需求,我们很容易就得到了结果,但是,我们如果需要统计标签里没有java的文章呢?首先,我们大概会想到用!去处理。
select * from tags where tag!='java'
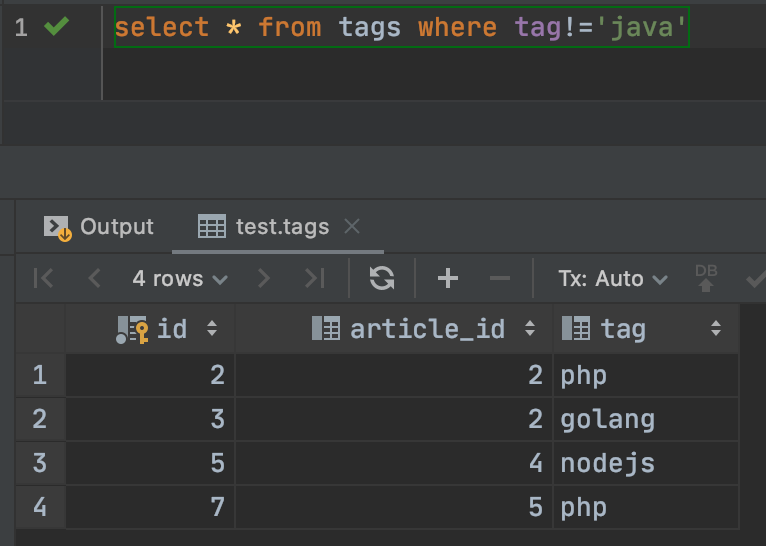
通过结果,我们可以发现 ,并不如预期,因为ariticle_id 为5的文章是有java这个标签的。当然不会这么简单了,要不然,这篇文章的意义何在呢?经过思考,很多人会想到创造一个只有标签的关联表去查询,例如这样:
select t.article_id,any_value(case when t.tag=targetTags.tagName then tag end ) as matchTag,any_value(t.tag),targetTags.tagName from tags t
left join (select 'java' as tagName from dual ) targetTags on t.tag=targetTags.tagName
group by t.article_id,targetTags.tagName
运行看结果
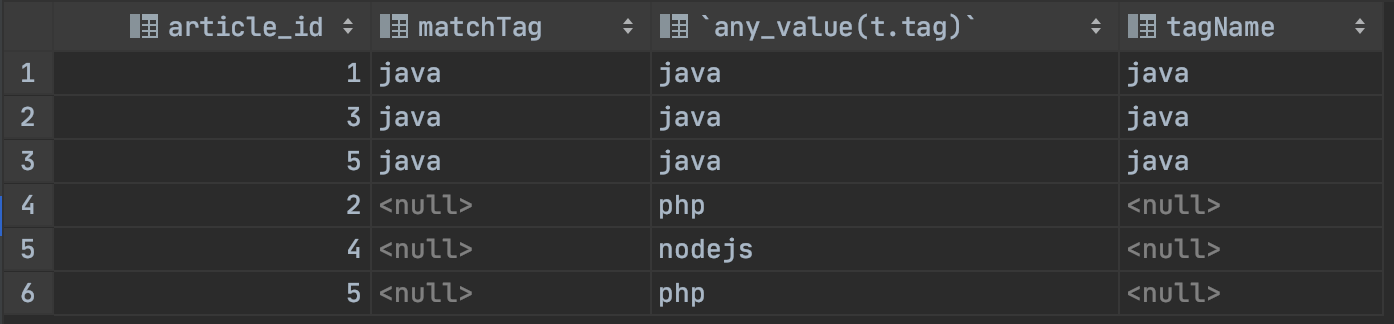
结果不满足预期,期望结果是 不管能否匹配到,tageName这一列,应该是永远有值的。但是由于我们在关联条件用的是=,那么就肯定会有不满足的情况,怎么办呢,我们要想一个办法让on 右边的条件恒等于。
select t.article_id,any_value(case when t.tag=targetTags.tagName then tag end ) as matchTag,targetTags.tagName from tags t
left join (select 'java' as tagName from dual ) targetTags on 1
group by t.article_id,targetTags.tagName
这样就到位了,运行看结果:
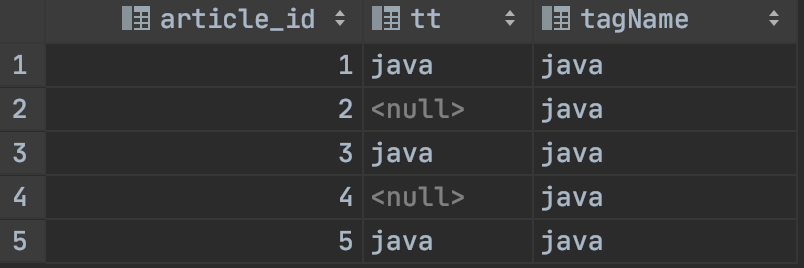
妥了,满足预期,那么这个最终的sql如下:
select * from (
select t.article_id,any_value(case when t.tag=targetTags.tagName then tag end ) as matchTag,targetTags.tagName from tags t
left join (select 'java' as tagName from dual ) targetTags on 1
group by t.article_id,targetTags.tagName
) tags_result
where tags_result.matchTag is null
结果如下:

下面再深入点,我们进行多个标签的不匹配查询,要统计出,没有java,和没有php的文章。sql如下
select * from (
select t.article_id,max(case when t.tag=targetTags.tagName then tag end ) as matchTag,targetTags.tagName from tags t
left join (select 'java' as tagName from dual union all select 'php' as tagName from dual ) targetTags on 1
group by t.article_id,targetTags.tagName ) tags_result
where tags_result.matchTag is null
group by tags_result.article_id,tags_result.tagName
注意,由于排序的问题,这么的matchTag我们要用max函数包下,运行结果:
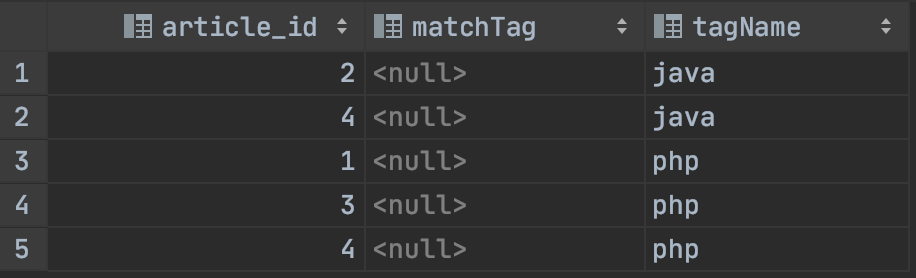
OK,基本可以满足做不匹配统计的需求了。当然,关系型数据库做统计还是差点意思,有条件的还是搞数仓吧。