1、安装虚拟机
VMware workstation
CentOS 镜像
安装Linux虚拟机:(在Win7上)
1)安装VMwareWorkstations(可修改配置)
2)添加CentOS镜像(启动安装 ->配置网络)
网络配置:NAT模式
网络重启:service network restart
关闭系统:shutdown -h now
2、远程连接
Xshell5
Xftp5
3、在Linux上搭建Hadoop集群
下载软件
1. Jdk:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2. Hadoop包:http://apache.fayea.com/hadoop/common/hadoop-2.7.2/
步骤:
1、修改/etc/hosts
2、配置JDK
安装:rpm -ivh jdk-8u101-linux-x64.rpm
vi /etc/profile
JAVA_HOME
source /etc/profile
java -version
3、配置SSH(免密码登录)
执行命令 ssh keygen -t rsa
ll .ssh/
cat xxx.pub >> authorized_keys
chmod 644 authorized_keys
ssh IP/HOSTNAME
4、安装及配置Hadoop
tar zxf hadoop-2.7.2.tar.gz
cd /opt/hadoop-2.7.2/etc/hadoop/
core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://bigdata:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.2/current/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>4320</value>
</property>
hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.7.2/current/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-2.7.2/current/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>staff</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>bigdata:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>bigdata:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>bigdata:18025</value>
</property> <property>
<name>yarn.resourcemanager.admin.address</name>
<value>bigdata:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>bigdata:18088</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>bigdata:50030</value>
</property>
<property>
<name>mapreduce.jobhisotry.address</name>
<value>bigdata:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/jobhistory/done</value>
</property>
<property>
<name>mapreduce.intermediate-done-dir</name>
<value>/jobhisotry/done_intermediate</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
slaves
bigdata
hadoop-env.sh
JAVA_HOME
5、格式化HDFS
hdfs namenode -format
‘16/09/0403:07:30 INFO common.Storage: Storage directory /opt/hadoop-2.7.2/current/dfs/namehas been successfully formatted.’
6、启动Hadoop集群
/opt/hadoop-2.7.2/sbin/start-all.sh
7、验证Hadoop集群
1)jps
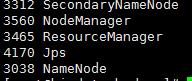
2) service iptables stop
关闭防火墙 或者 在防火墙的规则中开放这些端口
hdfs http://bigdata:50070
yarn http://bigdata:8088