
什么是Kafka
Kafka 是一个高吞吐量的、持久性的、分布式发布订阅消息系统
- 高吞吐量:可以满足每秒百万级别消息的生产和消费。
为什么这么快?
难道Kafka的数据是放在内存里面的吗?
不是的,Kafka的数据还是放在磁盘里面的
主要是Kafka利用了磁盘顺序读写速度超过内存随机读写速度这个特性。
所以说它的吞吐量才这么高
- 持久性:有一套完善的消息存储机制,确保数据高效安全的持久化。
- 分布式:它是基于分布式的扩展、和容错机制;Kafka的数据都会复制到几台服务器上。当某一台机器故障失效时,生产者和消费者切换使用其它的机器。
Kafka组件介绍
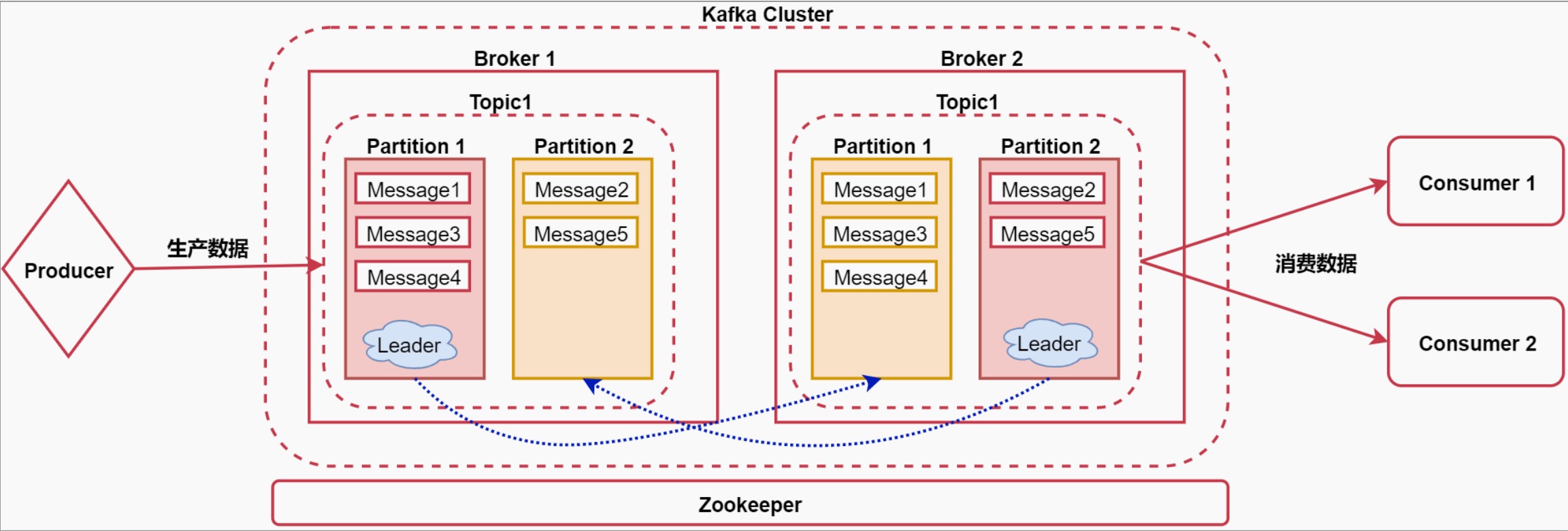
先看中间的Kafka Cluster
这个Kafka集群内有两个节点,这些节点称之为Broker
Broker:消息的代理,Kafka集群中的一个节点称为一个broker
在Kafka中有Topic的概念
Topic:称为主题,Kafka处理的消息的不同分类(是一个逻辑概念)。
如果把Kafka认为是一个数据库的话,那么Kafka中的Topic就可以认为是一张表
不同的topic中存储不同业务类型的数据,方便使用
在Topic内部有partition的概念
Partition:是Topic物理上的分组,一个Topic会被分为1个或者多个partition(分区),分区个数是在创建topic的时候指定。每个topic都是有分区的,至少1个。
注意:这里面针对partition其实还有副本的概念,主要是为了提供数据的容错性,我们可以在创建Topic的时候指定partition的副本因子是几个。
在这里面副本因子其实就是2了,其中一个是Leader,另一个是真正的副本
Leader中的这个partition负责接收用户的读写请求,副本partition负责从Leader里面的partiton中同步数据,这样的话,如果后期leader对应的节点宕机了,副本可以切换为leader顶上来。
在partition内部还有一个message的概念
Message:称之为消息,代表的就是一条数据,它是通信的基本单位,每个消息都属于一个partition。
小结:Broker>Topic>Partition>Message
接下来还有两个组件,看图中的最左边和最右边
Producer:消息和数据的生产者,向Kafka的topic生产数据。
Consumer:消息和数据的消费者,从kafka的topic中消费数据。
这里的消费者可以有多个,每个消费者可以消费到相同的数据
最后还有一个Zookeeper服务,Kafka的运行是需要依赖于Zookeeper的,Zookeeper负责协调Kafka集群的正常运行。
Kafka中的生产者和消费者
Producer:Producer默认是将数据随机发送到指定Topic的分区中的,也可以根据用户设置的算法来根据消息的key来计算输入到哪个partition里面
针对producer的数据通讯方式:同步发送和异步发送
同步是指:生产者发出数据后,等接收方发回响应以后再发送下个数据的通讯方式。
异步是指:生产者发出数据后,不等接收方发回响应,接着发送下个数据的通讯方式。具体的数据通讯策略是由 acks 参数控制的
acks默认为 1 ,表示需要Leader节点回复收到消息,这样生产者才会发送下一条数据
acks:all ,表示需要所有Leader+副本节点回复收到消息(acks=-1),这样生产者才会发送下一条数据
acks:0 ,表示不需要任何节点回复,生产者会继续发送下一条数据
针对这块在面试的时候会有一个面试题:Kafka如何保证数据不丢?
其实就是通过acks机制保证的,如果设置acks为all,则可以保证数据不丢,因为此时把数据发送给kafka之后,会等待对应partition所在的所有leader和副本节点都确认收到消息之后才会认为数据发送成功了,
所以在这种策略下,只要把数据发送给kafka之后就不会丢了。
如果acks设置为1,则当我们把数据发送给partition之后,partition的leader节点也确认收到了,但是leader回复完确认消息之后,leader对应的节点就宕机了,副本partition还没来得及将数据同步过去,所以会存在丢失的可能性。
不过如果宕机的是副本partition所在的节点,则数据是不会丢的。
如果acks设置为0的话就表示是顺其自然了,只管发送,不管kafka有没有收到,这种情况表示对数据丢不丢都无所谓了。
Consumer
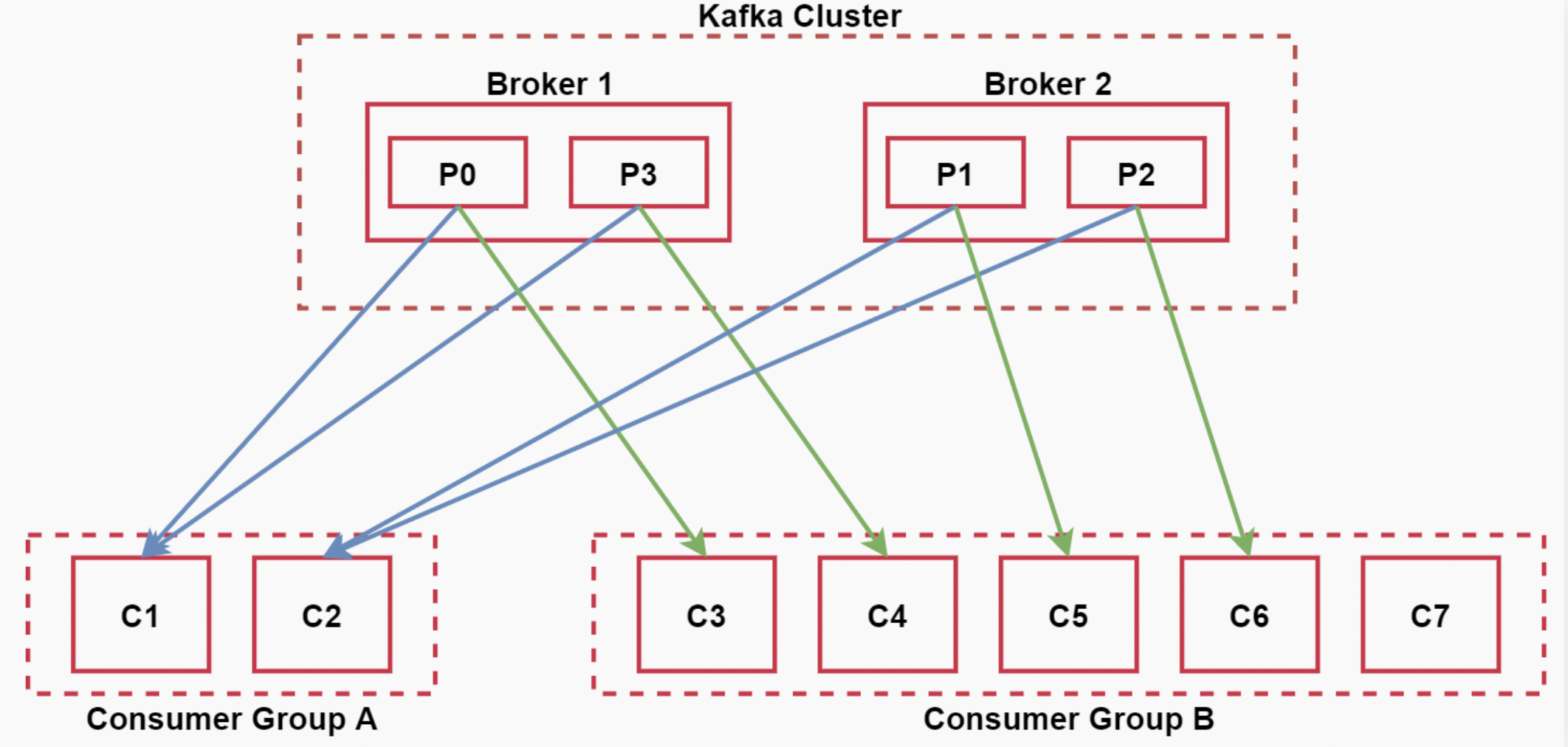
在消费者中还有一个消费者组的概念
每个consumer属于一个消费者组,通过group.id指定消费者组
那组内消费和组间消费有什么区别吗?
- 组内:消费者组内的所有消费者消费同一份数据;
注意:在同一个消费者组中,一个partition同时只能有一个消费者消费数据
如果消费者的个数小于分区的个数,一个消费者会消费多个分区的数据。
如果消费者的个数大于分区的个数,则多余的消费者不消费数据
所以,对于一个topic,同一个消费者组中推荐不能有多于分区个数的消费者,否则将意味着某些消费者将无法获得消息。
- 组间:多个消费者组消费相同的数据,互不影响。
看下面的图,加深一下理解
Kafka存储机制和容错机制
Message
每条Message包含了以下三个属性:
- offset 对应类型:long 表示此消息在一个partition中的起始的位置。可以认为offset是partition中Message的id,自增的
- MessageSize 对应类型:int32 此消息的字节大小。
- data 是message的具体内容。
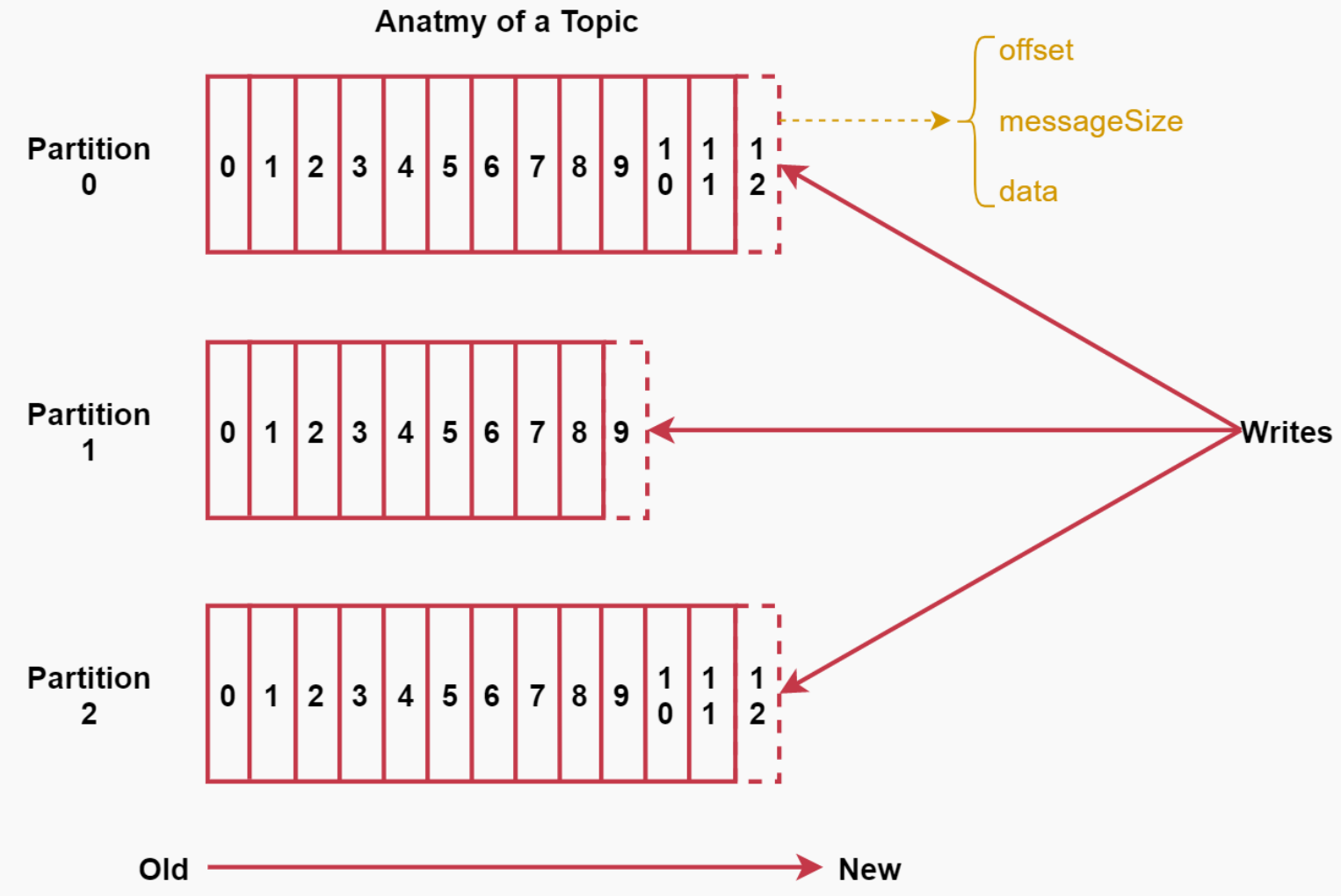
存储策略
kafak中数据的存储方式是这样的:
- 每个partition由多个segment【片段】组成,每个segment中存储多条消息,
- 每个partition在内存中对应一个index,记录每个segment中的第一条消息偏移量。
Kafka中数据的存储流程是这样的:
生产者生产的消息会被发送到topic的多个partition上,topic收到消息后往对应partition的最后一个
segment上添加该消息,segment达到一定的大小后会创建新的segment。
来看这个图,可以认为是针对topic中某个partition的描述
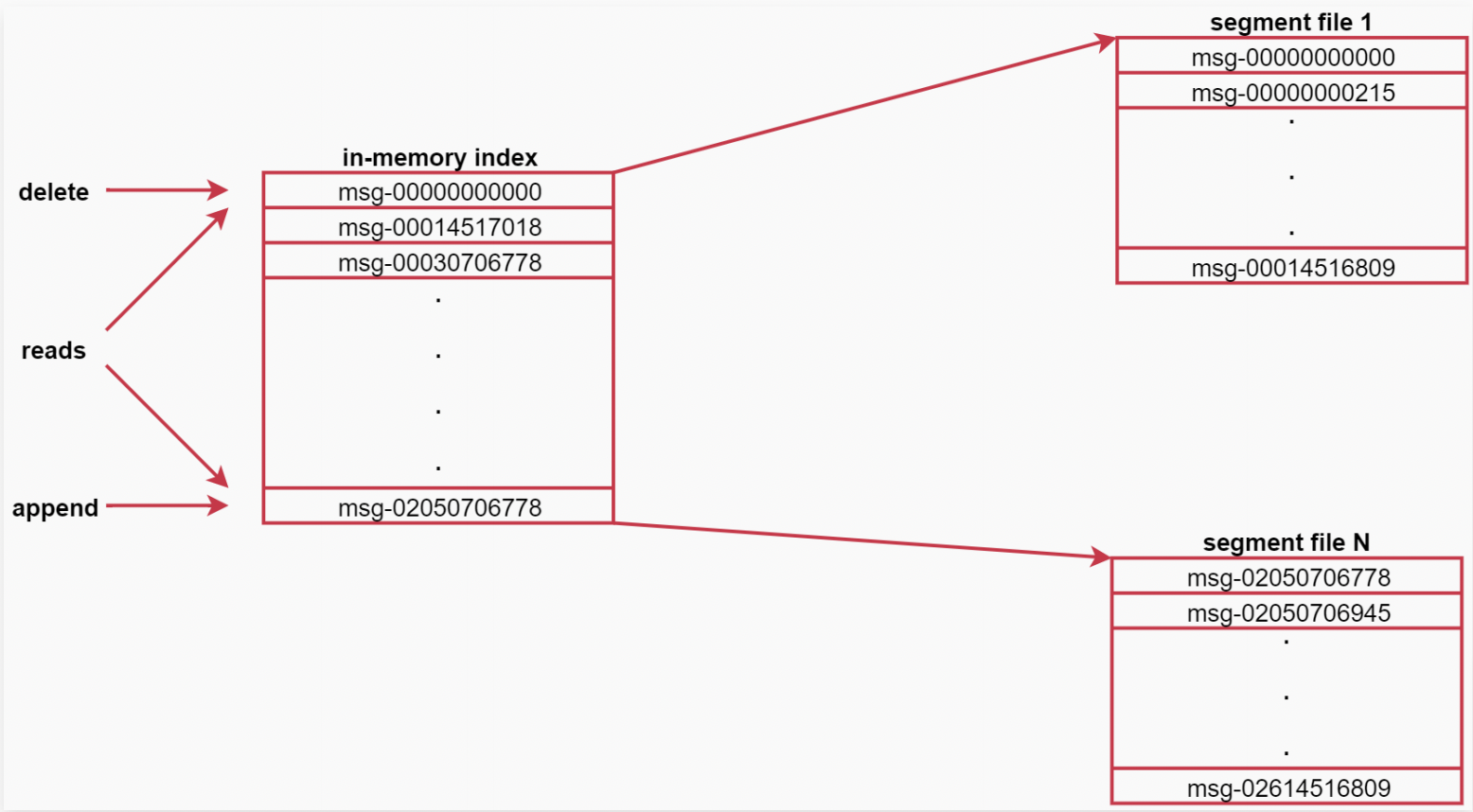
图中左侧就是索引,右边是segment文件,左边的索引里面会存储每一个segment文件中第一条消息的偏移量,由于消息的偏移量都是递增
的,这样后期查找起来就方便了,先到索引中判断数据在哪个segment文件中,然后就可以直接定位到具体的segment文件了,这样再找具
体的那一条数据就很快了,因为都是有序的。
容错机制
当Kafka集群中的一个Broker节点宕机,会出现什么现象?
在Kafka服务器集群先kill干掉一个broker进程
然后通过zookeeper查看Kafka节点状态

此时发现zookeeper的/brokers/ids下面只有2个节点信息
可以通过get命令查看节点信息,这里面会显示对应的主机名和端口号

然后再使用describe查询topic的详细信息,会发现此时的分区的leader全部变成了目前存活的另外两个节点
此时可以发现Isr(In-Sync Replica)中的内容和Replicas中的不一样了,因为Isr中显示的是目前正常运行的节点
所以当Kafka集群中的一个Broker节点宕机之后,对整个集群而言没有什么特别的大影响,此时集群会给partition重新选出来一些新的Leader节点

当Kafka集群中新增一个Broker节点,会出现什么现象?
新加入一个broker节点,zookeeper会自动识别并在适当的机会选择此节点提供服务

但是启动后有个问题:发现新启动的这个节点不会是任何分区的leader?怎么重新均匀分配呢?
1、Broker中的自动均衡策略(默认已经有)
auto.leader.rebalance.enable 默认值true
leader.imbalance.check.interval.seconds 默认值:3002、手动执行:
bin/kafka-leader-election.sh --bootstrap-server localhost:9092 --election-type preferred